

Despite achieving impressive performances on various tasks, modern artificial intelligence (AI) systems have become complex black box models. A growing body of work aspires to open the box and understand its internal functioning. In this new article (Lambrechts et al., 2022), we follow this field of research by studying the internal representation that intelligent agents learn through reinforcement learning (RL), when those agents act in partially observable environments (POEs). In particular, the informational content of the memory of those agents is studied when the latter are trained to act optimally in maze and orientation tasks. In the following, we summarise this new article.
1. Intelligent agents with internal states
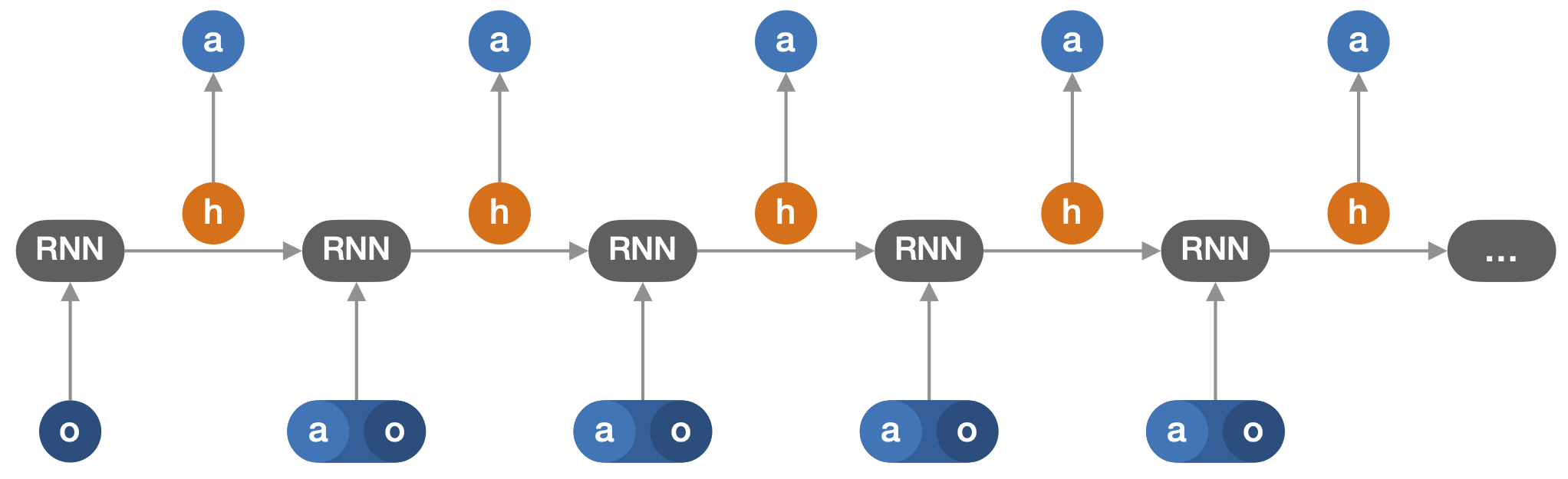
In RL, agents are tasked with finding an optimal policy for choosing their actions based on the history of past observations (o) and actions (a). As a consequence, the agents need to efficiently process that history by memorising and inferring appropriate information in order to act, optimally, at all later time steps. In practice, modern RL algorithms for POEs often model the policy with a recurrent neural network (RNN). RNNs maintain an internal state which is updated each time that a new action is taken and a new observation of the environment is received, as illustrated on Figure 1.
2. Optimal strategy with beliefs
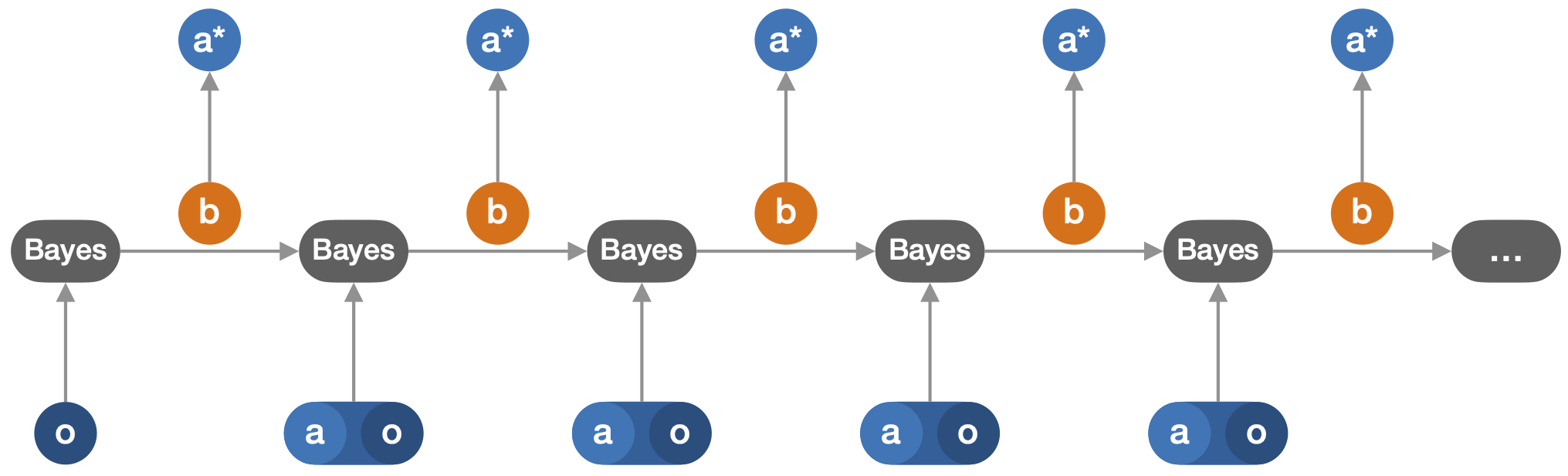
From the theory of optimal control, we know that the optimal policy in a POE can be written solely as a function of the posterior probability distribution of the state of the environment given the history, called the belief (b). In addition, the belief can be updated using Bayes’ rule based on the current belief only when taking a new action (a) and receiving a new observation (o), as illustrated on Figure 2. In other words, the belief is a sufficient statistic from the history for the optimal control at all later steps.
3. Correlation between internal states and beliefs
This similarity between the RNN update and the belief update (see Figures 1 and 2), knowing that the belief is a sufficient statistic for acting optimally, suggests that the internal state of the RNN may contain information about the belief state. In this work, we study whether RL agents that are trained to act optimally have their internal state that indeed conveys information about the belief. In practice, we measure the mutual information between internal states and beliefs resulting from interaction with the environments. In addition, we distinguish the belief of state variables that are relevant for the optimal control from the belief of state variables that are irrelevant for the optimal control. The results of this work show that the belief of state variables that are relevant for the optimal control is encoded in the internal states of RNN-based RL agents. In other words, the internal states h (see Figure 1) are correlated to the belief b (see Figure 2), as measured by the mutual information between h and b, for random histories generated in the environment.
4. Conclusions and future works
It is interesting to see that the belief filter of relevant state variables is implicitly approximated by a RNN when the latter is tasked at directly acting optimally based on the history. This conclusion also motivates future work where particular attention is paid to the ability of the RNN to efficiently reproduce the belief of the environments that are considered. Furthermore, this work suggests that the learning of RNN-based RL agents could be improved by biasing their internal states towards the belief, as has been achieved in other works. It also suggests a new way of biasing the internal state towards the belief, independently of the underlying architecture, by maximising the mutual information between the internal states and the belief.
Reference
Recurrent networks, hidden states and beliefs in partially observable environments. Gaspard Lambrechts, Adrien Bolland, Damien Ernst. In Transaction on Machine Learning Research, 2022.

Leave a comment