
Gaspard Lambrechts, Florent De Geeter, Nicolas Vecoven, Damien Ernst, and Guillaume Drion.
Link: https://hdl.handle.net/2268/260699.
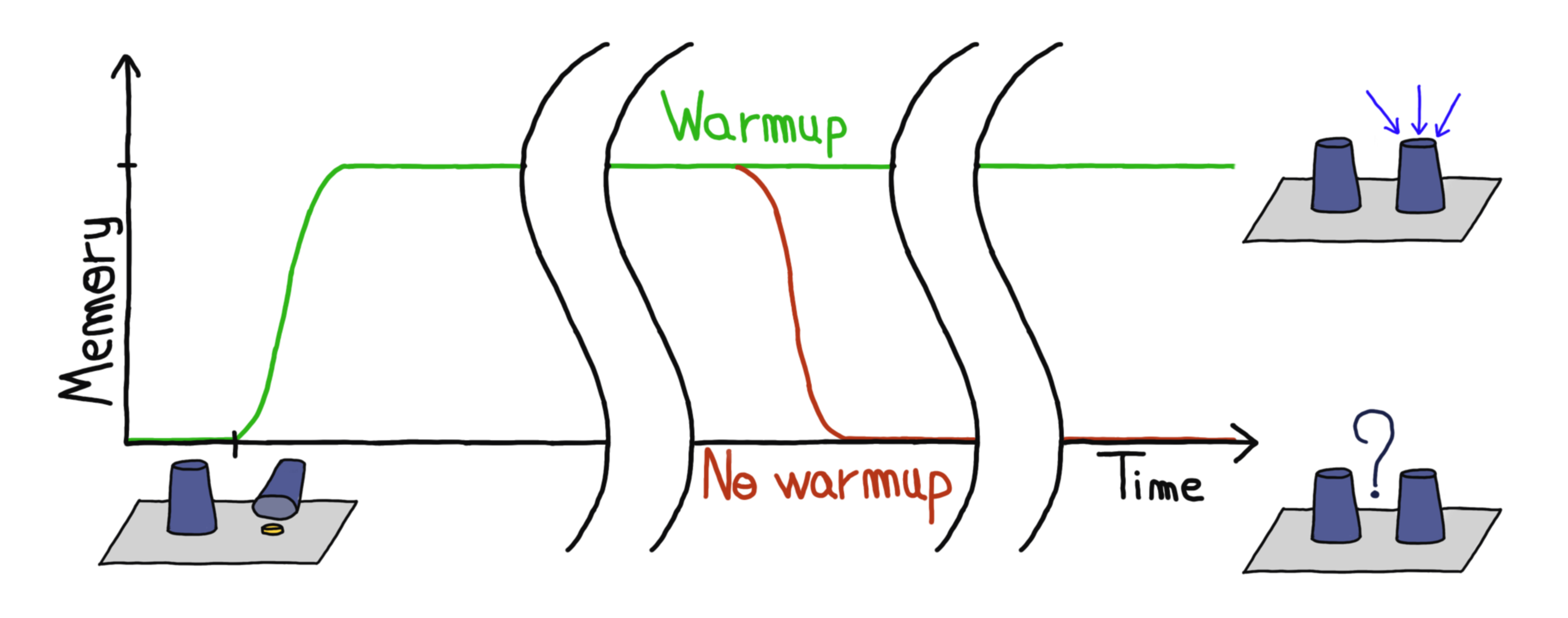
Recurrent neural networks (RNNs) are a special type of artificial neural networks that can be used to process sequences, such as time series or sentences, through an internal state that serves as a memory. However, training RNNs is known to be difficult, especially for long sequences. Indeed, when gradients are backpropagated through a high number of timesteps, they are more prone to either vanish or explode, making it difficult to learn long-term dependencies. Previous work (Vecoven et al., 2021) introduced RNNs with multistable dynamics and showed that it can improve the learning of such dependencies. In this new paper (Lambrechts et al., 2023), we expand this idea by first deriving a measure of multistability, called the VAA. This metric is then used to unveil the correlation between the reachable multistability of an RNN and its learning of long-term dependencies, both in a supervised and a reinforcement learning setting. Secondly, we establish a derivable approximation of our new measure. Gradient ascent steps can then be performed on a usual RNN using batches of sequences, in order to maximise that approximation. This aims at promoting multistability within the RNN’s internal dynamics, and it works for any RNN, including the classical GRU and LSTM networks. Finally, we test this new pretraining method, called the warmup, on both supervised and reinforcement learning benchmarks. RNNs pretrained with the warmup are shown to learn faster and better the long-term dependencies than their non-pretrained counterparts.
1. Multistability
Multistability is a property of dynamical systems that can be defined as the ability of a system to reach multiple stable states. In a few words, such a system can be seen as a ball on top of a hill, surrounded by two valleys. The ball will eventually stop in one of them, and stay there forever. Depending on the direction towards which the ball is pushed, it will land in a different valley. By observing in which one the ball has stopped, we can infer the direction of the push. This is the principle of a never-fading memory. In the case of a RNN, the ball is the RNN state, and the valleys are the attractors of the network’s dynamics. The direction of the push is the input of the network. The more valleys the network has, the more information it can store. This is why multistability is a desirable property for RNNs.
2. Measuring multistability – VAA
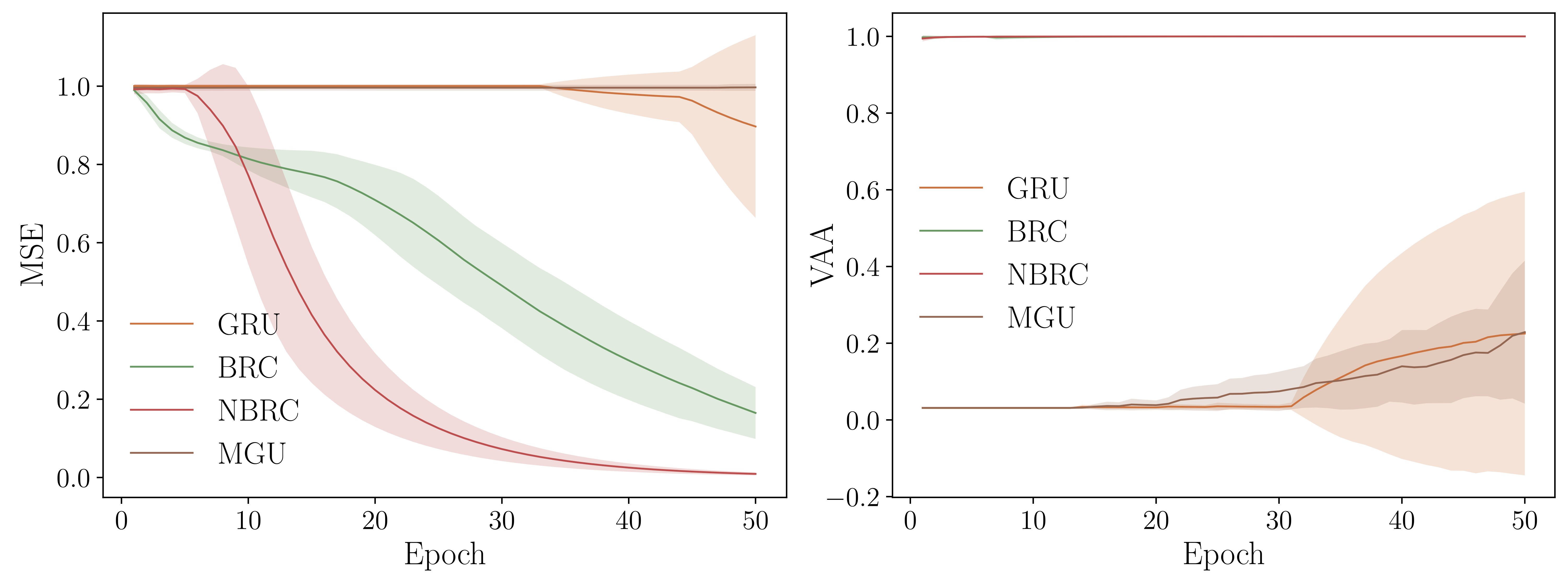
In our paper, we define the reachable multistability as the number of stable states that can be reached by the network, given a set of inputs. The more stable states the network can reach, the more multistable it is. To measure that, we introduce the variability amongst attractors (VAA). This metric basically simulates the behavior of a system for a large number of timesteps starting from a set of states and with a constant input. After that, the final states are compared to each other, and the more different they are, the closer to 1 the VAA is. Making experiments on long-term dependencies benchmarks has revealed a certain correlation between the VAA and the improvement of performance on such benchmarks (Figure 1).
3. Promoting multistability – Warmup
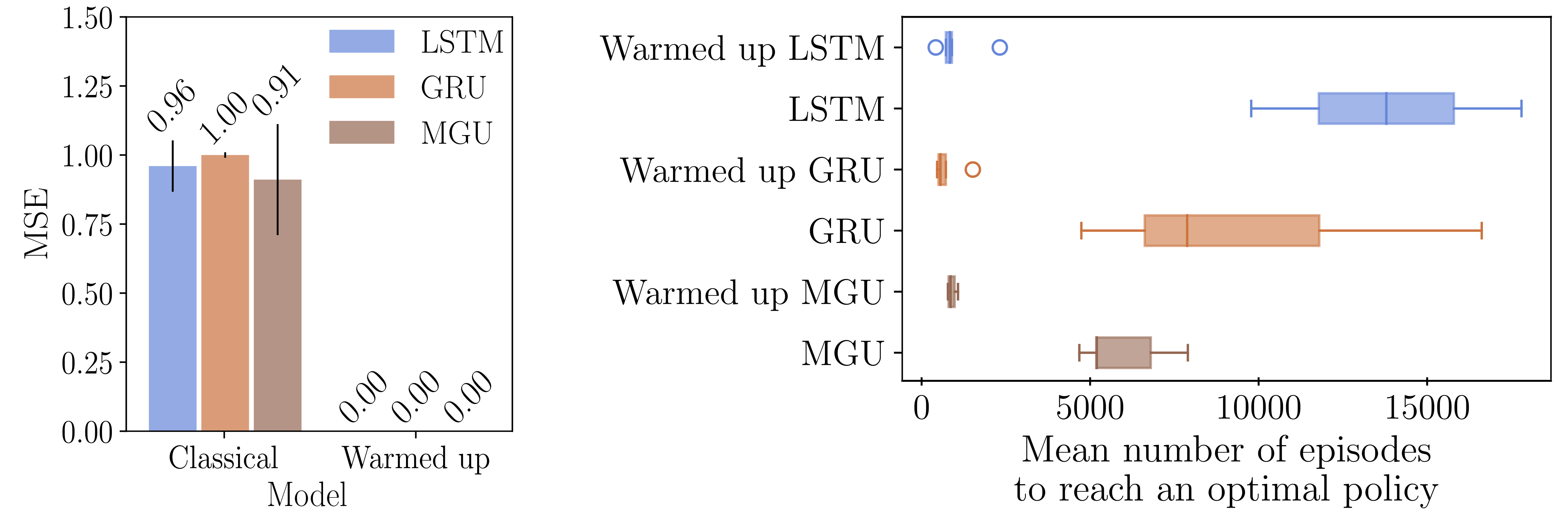
The VAA allows us to measure the multistability of a RNN. However, it is not derivable, which prevents from using backpropagation to maximise it. To overcome this issue, we introduce a derivable approximation of the VAA, the VAA*, as well as a new pretraining algorithm, the warmup. The VAA* works similarly to the VAA. The warmup consists in maximising the VAA* of a RNN by performing gradient ascent steps on batches of sequences. Indeed, each batch of sequences is fed to the RNN, which gives us a batch of hidden states. We then compute the VAA* on these hidden states, and finally apply a gradient ascent step on the RNN’s parameters. This process is repeated a number of times, after which the RNN is trained on the actual task. The warmup is shown to improve the learning of long-term dependencies on both supervised and reinforcement learning benchmarks (Figure 2), while being computationally cheap and unsupervised.
References
Vecoven et al., 2021: Vecoven, N., Ernst, D., & Drion, G. (June 2021). A bio-inspired bistable recurrent cell allows for long-lasting memory. PLoS ONE, 16 (6).
Lambrechts et al., 2023: Lambrechts, G. , De Geeter, F. , Vecoven, N. , Ernst, D., & Drion, G. (August 2023). Warming up recurrent neural networks to maximise reachable multistability greatly improves learning. Neural Networks, 166, 645-669.

Leave a comment